Project description:
 Service summary: Data Science Workspace (DSW) is a cloud platform for Data Science teams and individuals with the following abilities:
Service summary: Data Science Workspace (DSW) is a cloud platform for Data Science teams and individuals with the following abilities:
- Change computing performance and libraries in one click, without leaving Jupyter Lab/Notebook
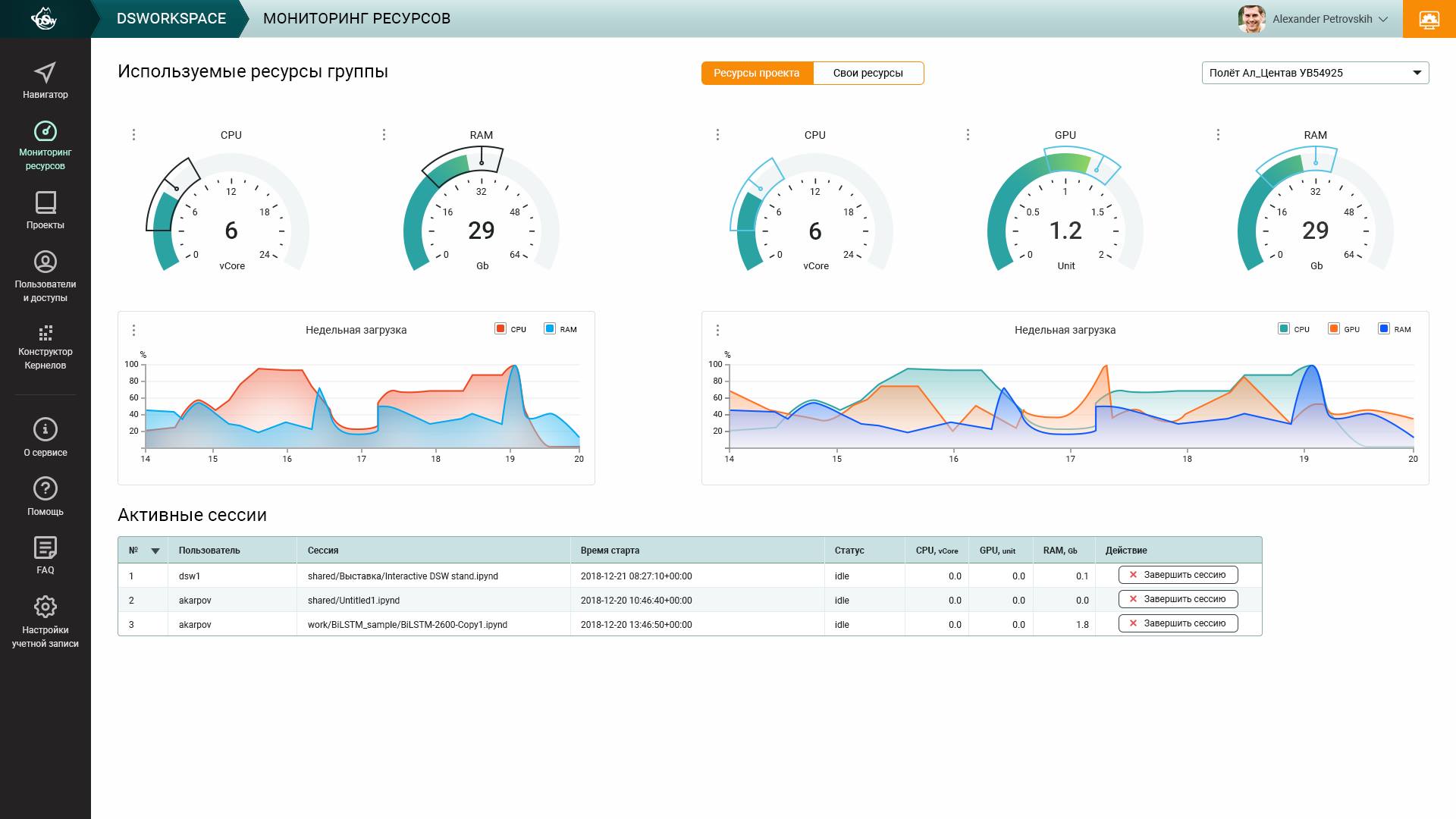
- Monitor sessions and resource usage
- Save results into project network folder with access control
It covers R&D stage, supports the pay-as-you-go approach. In the near future, DSW would support distributed computing (SPARK) and container builder for custom ML libraries set.
Benefits for companies:
- Increase Data Science productivity with ready to use workspace
- Reduce data loses and leaks by saving all data-marts and research results in a network folder with access control
- Ability to use expensive high-end servers on demand
- Monitor team performance in terms of resource usage
Target audience:
- Companies that have Data Scientists and data for research.
- Students of universities and Data Science education training.
- Individual Data Scientists who want to start scalable research and avoid unnecessary DevOps.
Market: Global cloud analytics market is $8,3B with a growing GPU-as-a-Service approach for Deep Learning.
Technologies and approaches: Web portal, integrated with Jupyter Lab / Notebook at front. Many techs under, including VMWare, Kubernetis, Docker, Jupyter Hub, GitLab, Anaconda Distribution.
Readiness level: Produced technical release and started sales.
Description: We saw a growth of global demand in prediction models development, using machine learning. Production and insurance companies joined to telecom and banking.
Since Machine Learning (ML) is a new way of programming complicated logic, companies need tools, servers and qualified DevOps to support ML-engineers. Another challenge was computing resource monitoring and efficient usage – there was no simple tool for that. Therefore, we decided to automate most of these processes in order to speed-up researches.
Development phases: This service we built from the ground up. After market analysis, when basic investment budget was calculated and approved, I provided about 15 customer in-depth interviews with data engineers and their managers, university teachers, hackathon managers in order to understand their needs and find frequently requests. As a result, I created product backlog with about 26 product features combined in problematic groups.
In a month, we developed a demo version for an internal presentation. Next month we developed MVP for AI conference.

The technical release took about 4 months due to technological complexity. Taking into consideration that we worked in a large slow system integration company, our team ran fast.
In parallel with technical release production, I built support SLA process and developed sales-kit with pricing, benefits, comparison with competitors. Then I started sales enablement and first presales.
Product challenges: We had to improve open-source software in order to close security vulnerabilities.
If a company’s data is not in the cloud, they would like to move it to the cloud-first and requires prerequisites like S3 compatible storage, basic self-service automation and billing. Cloud providers should automate basic data services first.
DSW almost passed a Product Discovery stage, from idea to MVP and first sales. During customer research, I discovered another segment of companies that asked for ready to use industry and case specific machine learning models. So the MiGA product appeared.